k-nearest neighbor
KNN

The k-nearest neighbor algorithm is a supervised machine learning algorithm that can be used to solve both classification and regression problems.
Classification usage
Let us understand the algorithm using the below figure where we have two classes of data points ( A and B).
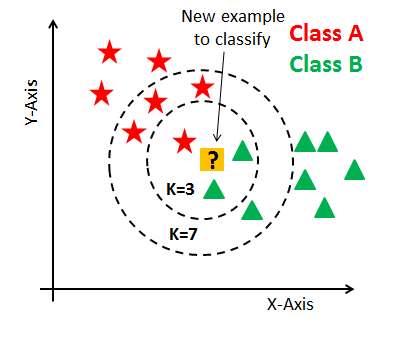
Source: www.kdnuggets.com
The first step is to determine the K value ( 'k' here is the number of nearest data points from the new data point). Let us take k = 3 as per the above figure. We can see that 2 out of 3 neighbors are from class B. So, in this case we go with the majority votes, i.e., the new data point will be classified as class B. We can use either Euclidean or Manhattan distance to get the nearest neighbor.
Regression usage
Below we can see the difference in the regression and classification usage. We will focus on the left figure for regression under this topic.
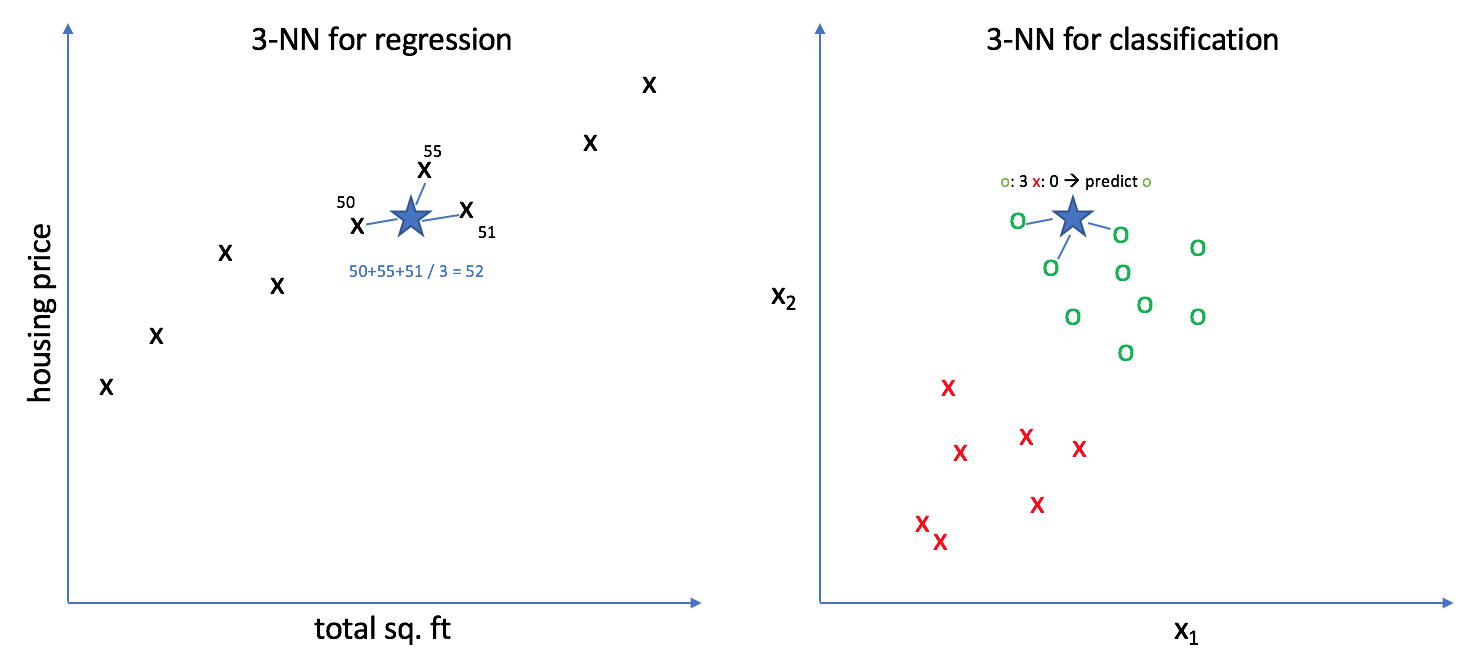
Similar to the classification problem, here also we need to come up with a k value. If the k value is 3 and the new data point is the bigger blue star as in the figure, then predicted value for the new data point will be the mean of the 3 nearest data points. In this case it will be 52. The distance for the nearest neighbor is calculated with either Euclidean or Manhattan distance.
Selecting K value
Elbow method is used to basically get the value of k which will give the lowest WCSS(within cluster sum of square).
In this method a loop is run from k value 1 to n. For each value of K, the algorithm goes through all the steps that were mentioned above. For K =1, WCSS value will be very high and as the number of k value decreases the WCSS will decrease as we can see from below figure.


Comments
Post a Comment