Ensemble Technique 2 : AdaBoost
AdaBoost


Source: miro.medium.com
Boosting Technique
As we can see from the above figure, suppose the original data is D1 and the trained classifier seen below is a base learner BL1(say). BL1 can be any model/algorithm provided with a sample of data to train. After training the model, when the original data is used to validate the model, the incorrectly classified records are further treated by moving them to a next base learner (BL2). Now the BL2 will be trained with those wrong classified records and further if they classify some more records incorrectly then again a new base learning is created (BL3) and this process continues till we specify some limits to the base learner creation. This is in general how a boosting technique works.
Adaboost
Let us see how an Adaboost technique works for that we need to undergo few steps. Consider we have a dataset with 7 records and 3 features/columns.
Step1

Provide equal weights to all the records as shown in the above table (1/7).
Step2

In this stage we create our first base learner (BL1) which is created with the help of decision tree. In this case unlike in the general decision tree algorithm, we just have one depth here as seen in the above figure. This decision tree is called as stump. One thing to keep in mind is we need to create as many number of stumps as many features we have. In this scenario we have 3 features (Feature1, Feature2, Feature3) ,so we have to create 3 stumps on each features, where the feature will be in the root node position in the sequential manner. For better understanding consider the above figure, say this is the first stump so the blue colored node will be Feature1 and the two green coloured nodes will be Feature2 and Feature3.
The selection of the stump among the three will be based on the entropy values. So, the stump with the lowest entropy value is selected.
Now we need to calculate the total error in the BL1/selected stump. Suppose in this case we have only one wrong classification in the 7 total records then in that case the total error will be 1/7 (number of errors/ total number of records).
Step3
In this step we need to calculate the performance of the stump.

where TE is the total error
Once we substitute the value of TE as 1/7 in the formula we get the performance as 0.896
Step4
We need to update the sample weight that is increase the weight of wrongly classified records and decrease the weight of the right classification.
Formula for new sample weight are:
Incorrectly classified Sample Weight = Sample Weight * e^(Performance) = 0.349
Correctly classified Sample Weight = Sample Weight * e^(Performance) = 0.05
Now we need to update the weights of each records.

We can see an additional column named normalised weight is added which is the normalised version of the updated weight (the sum of the updated column was 0.649 and to make it standardized we need to divide each weight by 0.649).
Step5
Now using normalised weight value, we create a new dataset. The dataset based on the updated weight values selects the wrongly classified records for training our new stump/Base learner(BL2). To make this new dataset , the algorithm will divide it into buckets.

Now, our algorithm we will 7 iterations to select different records from old dataset. Suppose in first iteration, it selects a random value of 0.03 then it will check the value presence in the bucket. In this case, the first bucket record will be selected and populated in the new dataset. Here, the probability of selecting the wrongly classified records is maximum due to the higher range value of the bucket.
Again using the new dataset, algorithm will create second base learner(BL2)/stump. Like wise step 2 and other steps will take place here. We will consider that situation with lesser error rate compared to the initial state.
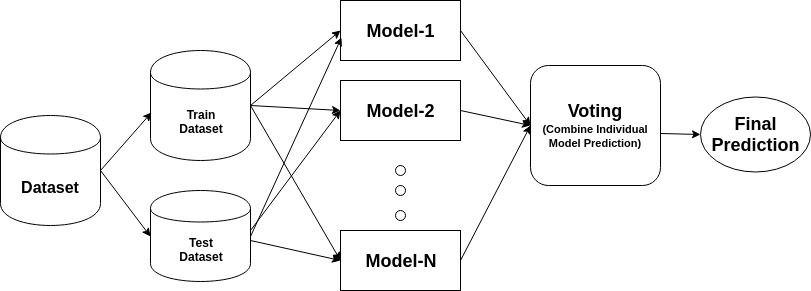
Suppose we have created in total of 3 base learners/stumps sequentially finally. Once the test data is passed to these stumps we get an output from each. Based on the voting classifier, majority of the value gets selected as we have seen in random forest also.
As I mentioned in the beginning, the main motive of the algorithm is to convert the weak learner into stronger ones.
Reference:
- https://www.mygreatlearning.com/blog/adaboost-algorithm/
- YouTube Channel - Krish Naik
- Wikipedia



Comments
Post a Comment