K means clustering
K means clustering

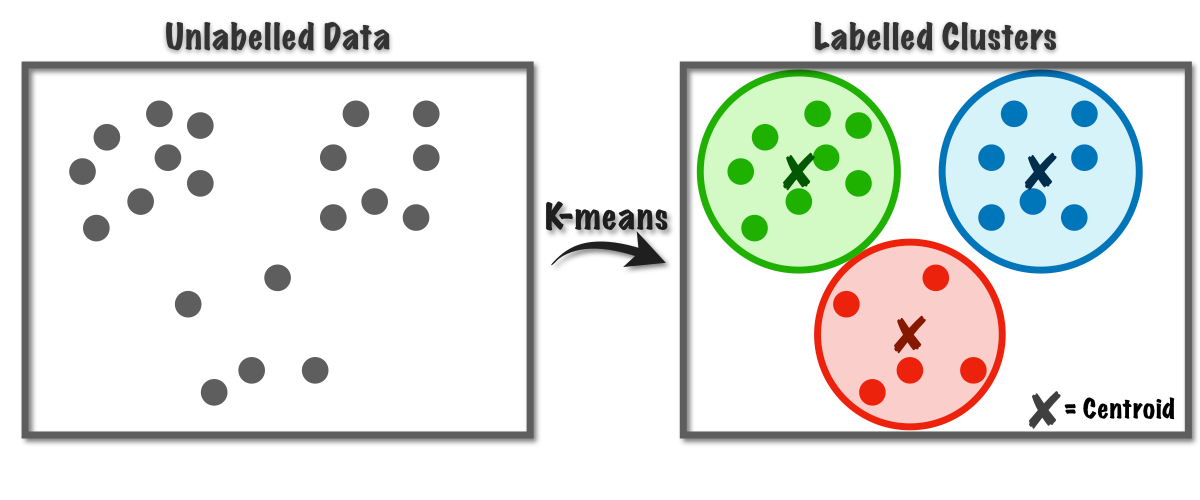
K-means is a non-parametric method of clustering where we pre define the number of clusters(non-parametric means computation complexity depends in number of samples). It is an unsupervised machine learning technique.

Source: miro.medium.com
- Determine K value: K value is basically how many centroids is needed for our data to form the best clusters. Here we can take any value for beginning.
- Initialize K points (randomly) as cluster centers in the plane(K = 3 in this case)
- Find the distance between the points nearer to the centroids: Here we can calculate the distance either using Euclidean and Manhattan Distance (Click here to know more about these distance). Based on the shortest distance from the centroids, clusters are formed.
- Select group and find mean value: For each group/cluster, the algorithm calculates the mean value of all the data points. Then the centroids are moved to the average value position for each clusters. Again we will repeat from the step 3 and each time the centroids gets updated. This process will continue till the movement of centroids are fixed.
Selecting K value
Elbow method is used to basically get the value of k which will give the lowest WCSS(within cluster sum of square).
In this method a loop is run from k value 1 to n. For each value of K, the algorithm goes through all the steps that were mentioned above. For K =1, WCSS value will be very high and as the number of k value decreases the WCSS will decrease as we can see from below figure.
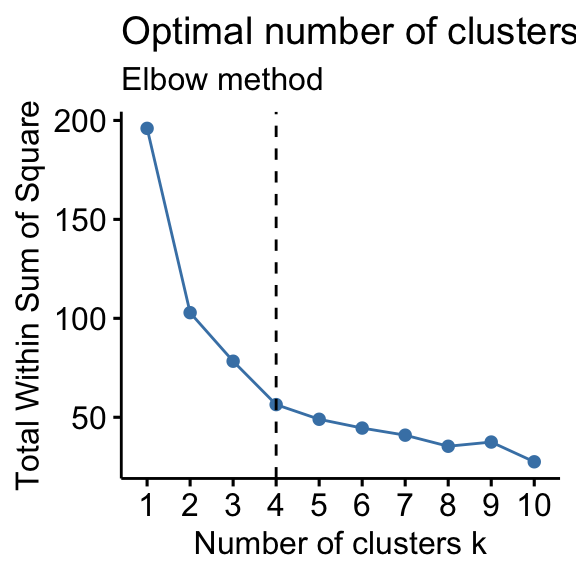
Source: www.datanovia.com
To select the K value, check for that value of K which is having an abrupt(sudden) decrease. In the above case, k value selected is 4. Also after 4 we can see the value is more or less normalized.
- Wikipedia
- YouTube Channel - CodeEmporium
- YouTube Channel - Krish Naik



{kind=link}
Comments
Post a Comment