Hyper parameter tuning: Grid Search CV VS Randomized Search CV

Hyperparameters are the variables that is defined by the developer of the model in order to get the best model possible. For example, max_depth and n_estimators in Random Forest.
There are multiple ways to setup the these hyperparameters. Two basic methods are Grid and Random Search.
Grid Search
The way GS will work is such that it will take a combination of each and every hyperparameters that is decided to use. It is a very efficient method in terms of getting the best possible hyperparameters. But as there will be multiple combinations along with cross validation, it will be a time consuming and expensive business.
Some important arguments of Grid Search CV
1. estimator – A scikit-learn model
2. param_grid – A dictionary with parameter names as keys and lists of parameter values.
3. scoring – The performance measure. For example, ‘r2’ for regression models, ‘precision’ for classification models.
4. cv – An integer that is the number of folds for K-fold cross-validation.
5. verbose - Controls the verbosity:, the higher the more messages.
6. n_jobs- It will help in allocating the CPU for the model execution. Keep -1 as value in order to automate the process.
Random Search
Random search tries random combinations of a range of values (we have to define the number iterations). It is good in testing a wide range of values and normally it reaches a very good combination very fast, but the problem that it doesn’t guarantee to give the best parameters combination.
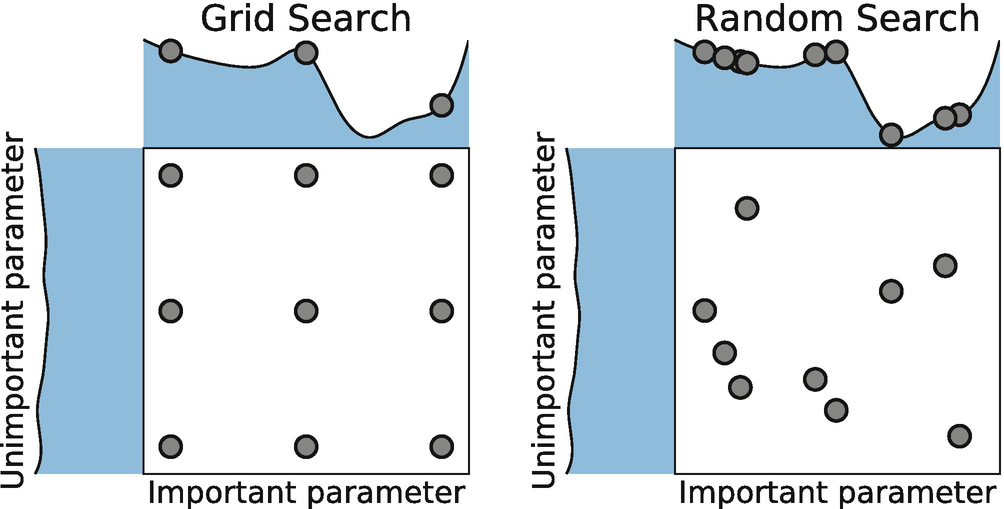
One thing that we can try doing is applying the random search CV first on the model and from that use the best parameters as param_grid for Grid search CV. In this way we can make use of both the methods and can come to a very good conclusion without taking enough time.
Quora: Mazen-Aly



Comments
Post a Comment